




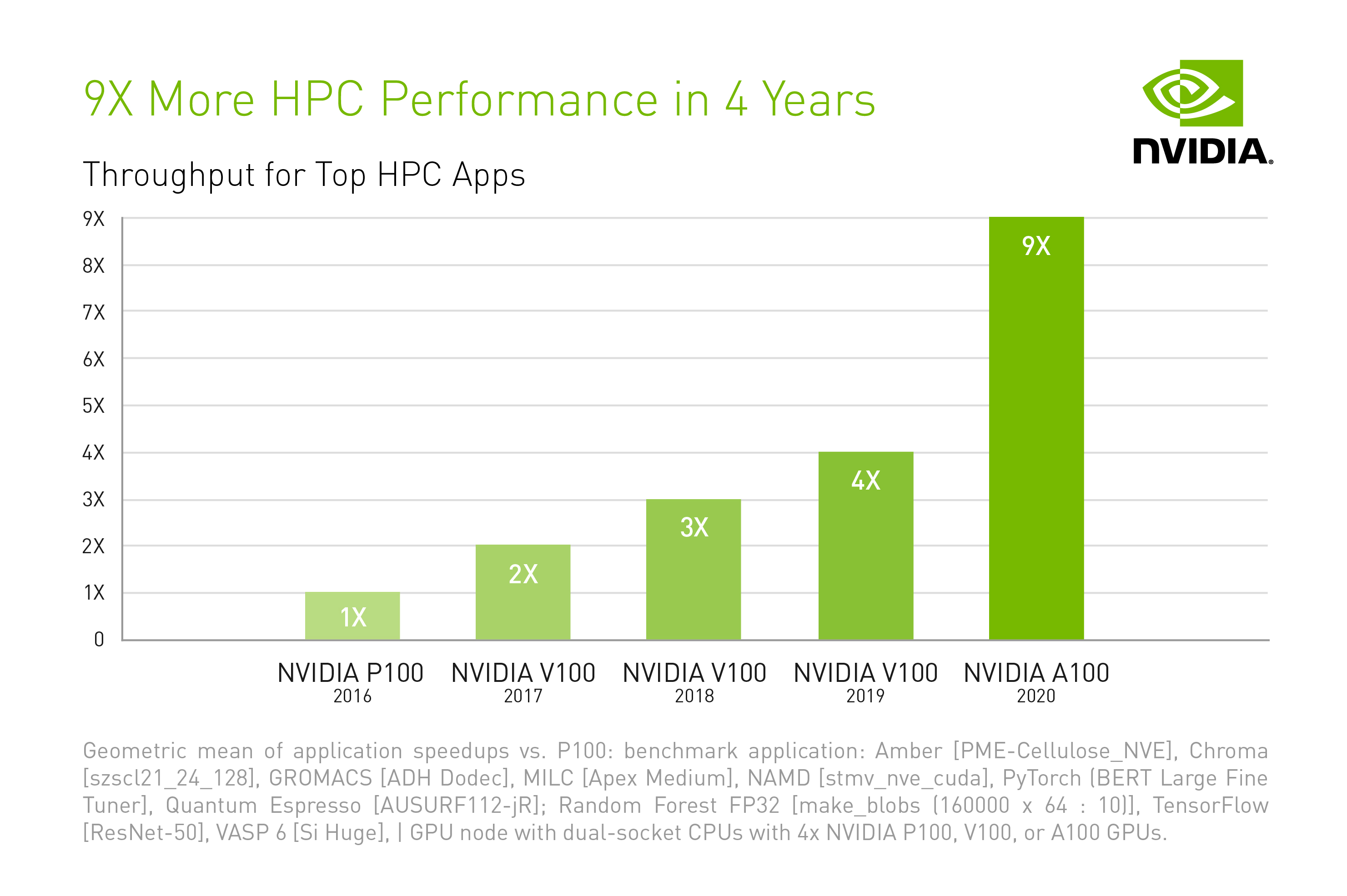
 The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale for AI, data analytics and HPC to tackle the world’s toughest computing challenges.
The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale for AI, data analytics and HPC to tackle the world’s toughest computing challenges.
Advanced Clustering Technologies offers systems that integrate this latest addition to the NVIDIA produce line, which as the engine of the NVIDIA data center platform can efficiently scale up to thousands of GPUs. Using new Multi-Instance GPU (MIG) technology, A100 can be partitioned into seven smaller GPUs to accelerate workloads of all sizes.
A100’s third-generation Tensor Core technology now accelerates more levels of precision for diverse workloads, speeding time to insight as well as time to market. A100 accelerates all major deep learning frameworks, and over 650 HPC applications, and containerized software from NGC helps developers easily get up and running.



 Advanced Clustering Technologies is offering educational discounts on NVIDIA A100 GPU accelerators.
Advanced Clustering Technologies is offering educational discounts on NVIDIA A100 GPU accelerators.
Higher performance with fewer, lightning-fast nodes enables data centers to dramatically increase throughput while also saving money.
Advanced Clustering’s GPU clusters consist of our innovative ACTblade compute blade products and NVIDIA GPUs. Our modular design allows for mixing and matching of GPU and CPU configurations while at the same time preserving precious rack and datacenter space.
Contact us today to learn more about the educational discounts and to determine if your institution qualifies.
NVIDIA, the NVIDIA logo, and are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries. Other company and product names may be trademarks of the respective companies with which they are associated. © 2021 NVIDIA Corporation. All rights reserved.
ACTserv x2440c
ACTserv x2440c is a flexible 2U dual socket “Sapphire Rapids” Xeon system with support for 4x dual slot GPUs for AI training or 8x single slot GPUs for AI inference.

-

CPU
2x up to 60 core Intel Xeon (Sapphire Rapids)
-

MEMORY
16x DDR5 4800MHz DIMM sockets (Max: 2 TB)
-

STORAGE
2x 3.5″ & 4x 2.5″ SATA,SSD,NVMe drive bays (Max: 61 TB)
-

ACCELERATORS
Max 4x NVIDIA Tesla, AMD accelerators
-

CONNECTIVITY
Onboard 2x 10Gb NICs & Optional: 10GbE, InfiniBand, OmniPath, 100GbE, 50GbE
-

DENSITY
2U rackmount chassis with redundant power
ACTserv x4411c
Our ACTserv x4411c is a GPU powerhouse for AI and HPC with 2x Intel Xeon Sapphire Rapids series CPUs and up to 8x GPUs

-
CPU
2x up to 60 core Intel Xeon (Sapphire Rapids)
-
MEMORY
32x DDR5 4800MHz DIMM sockets (Max: 4 TB)
-
STORAGE
8x 3.5″SATA,NVMe drive bays (Max: 50 TB)
-
ACCELERATORS
Max 8x NVIDIA Tesla accelerators
-
CONNECTIVITY
Onboard 2x 10Gb NICs & Optional: 10GbE, 40GbE, InfiniBand, OmniPath, 100GbE
-
DENSITY
4U rackmount chassis with redundant power
ACTserv e4411c
Our ACTserv e4411c is a GPU powerhouse for AI and HPC with 2x AMD EPYC Genoa 9004 series CPUs and up to 8x GPUs

-
CPU
2x up to 128 core AMD EPYC Genoa/Bergamo
-
MEMORY
24x DDR5 4800MHz DIMM sockets (Max: 3 TB)
-
STORAGE
8x 3.5″SATA,NVMe drive bays (Max: 176 TB)
-
ACCELERATORS
Max 8x NVIDIA Tesla accelerators
-
CONNECTIVITY
Onboard 2x 10Gb NICs & Optional: 10GbE, InfiniBand, OmniPath, 100GbE, 50GbE
-
DENSITY
4U rackmount chassis with redundant power
ACTserv e2471c
Our ACTserv e2471c is a perfect balance for AI and HPC applications with 1x AMD EPYC Genoa/Bergamo CPUs, 4x GPUs and storage.

-
CPU
1x up to 128 core AMD EPYC Genoa/Bergamo
-
MEMORY
12x DDR5 4800MHz DIMM sockets (Max: 1.501953125 TB)
-
STORAGE
6x 3.5″SATA,SSD,NVMe drive bays (Max: 92 TB)
-
ACCELERATORS
Max 4x NVIDIA Tesla accelerators
-
CONNECTIVITY
Onboard 2x 1Gb NICs & Optional: 10GbE, InfiniBand, OmniPath, 100GbE, 50GbE
-
DENSITY
2U rackmount chassis with redundant power